지금까지 우리는 Supervised Learning에 대해서 배웠습니다. 그동안에 Linear regression, logistic regression, Neural Networks 그리고 Support Vector Machine 까지의 알고리즘들을 공부했었습니다.
이번에는 Unsupervised Learning에 대해서 알아보겠습니다. Unsupervised Learning은 결과가 주어지지 않는 입력되는 데이터들(Unlabled dataset)만을 분석하여 연관있는 것들을 찾고 그룹핑을 하는 머신 러닝의 방식입니다.
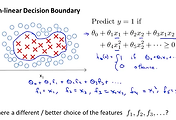
아래 그림은 Supervised Learning에서의 데이터와 Decision Boundary를 그래프로 나타낸 것입니다. 각각의 데이터는 x 인지 o 인지의 결과를 이미 가지고 있으며 이러한 data들을 예측하기 좋도록 구분하는 직선을 찾는 방식이였습니다.

이번에 배울 Unsupervised Learning은 결과가 없는 데이터만 있습니다. 아래 그림의 그래프에서와 같이 모두 같은 점으로 표현이 되는 데이터가 있습니다. 이들은 어떤 연관성을 가지고 있기 때문에 비슷한 것들 끼리 묶어서 나타낼 수 있을 것입니다. 아래의 예제에서는 2개의 그룹으로 묶을 수 있습니다. 이렇게 y값이 존재하지 않고 x만 존재하는 경우에 사용되는 알고리즘으로 Clustering algorithm이라고도 합니다.

현재 많은 분양에서 활용이 되고 있습니다. Market seqmetation과 같이 시장 점유율을 분석하는데도 사용이 되고 있으며 Social Network 상에 활동하는 사람들이 누구와 친하고 연결성이 강한지도 분석할 수 있습니다. 어떤 성향의 사람들인지도 알 수 있겠지요. 이러한 방식으로 구글이나 Facebook에서 추천 서비스에 활용이 되고 있습니다. 그외에도 컴퓨터 cluster나 우주 행성등의 연구에서도 활용이 되고 있습니다.

'Machine Learning' 카테고리의 다른 글
| 34. 자율적으로 학습하기 (Unsupervised Learning) : K means optimization (0) | 2016.08.20 |
|---|---|
| 33. 자율적으로 학습하기 (Unsupervised Learning) : K-means algorithm (0) | 2016.08.17 |
| 31. SVM (Support Vector Machine) 사용하기 (0) | 2016.08.15 |
| 30. SVM (Support Vector Machine) - Kernel에 대하여 (0) | 2016.08.14 |
| 29. SVM (Support Vector Machine) - Margin에 대하여 (0) | 2016.08.13 |



댓글