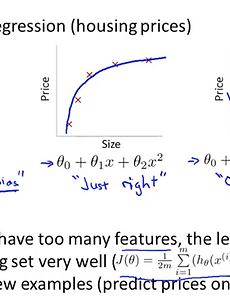
Regularization2 25. 머신러닝을 적용할때 고려할 내용들 (Model Selection, Bias, Variance, Learning Curves) 이번에는 머신러닝을 적용하여 여러분이 원하시는 무언가를 진행하고자 할때 생각해보면 좋은 내용들을 알아보겠습니다. 여러분이 정규화된 linear regression을 예측하는 모델을 만들었다고 생각해보겠습니다. 그런데 실제 학습된 결과가 실제 결과 보다 생각보다 많이 차이가 나서 적용하기 어렵다고 느껴질 때가 있을 것입니다. 이때 무엇을 해야 할까요 일반적으로 사람들은 다음과 같은 내용들을 하려고 생각합니다.1. 더 많은 데이터가 필요하다 - 2배, 10배 되는 데이터가 있으면 더욱 정확한 결과가 가능할 것이다라고 생각하지만 실제로는 그렇치 않습니다.2. features를 더 줄이자- overfitting 이 일어나는것 같아서 이를 방지하기 위해서 더 줄이려고 하는 경향이 생깁니다.3. features를 .. 2016. 7. 26. 18. 모델의 과최적화를 피하는 방법 (overfitting, regularization) 지금까지 우리는 두가지 모델에 대해서 배웠습니다.Supervised Learning에 대한 Linear regression 모델과 Logistic regression 모델을 배웠습니다.이 두가지 모델을 이용하면 상당히 많은 머신러닝에 대한 해답을 찾을 수 있을 것입니다. Overfitting 이시점에서 우리는 h함수에 대해서 조금더 알아보도록 하겠습니다.아래 그림은 Linear regression에서의 dataset을 그래프로 표현한 것입니다. 가장 왼쪽에 세타에 대한 1차방정식으로 h함수를 정의했다고 생각합시다. 이때 직선을 그리면 그래프와 같이 될 것입니다. 실제 데이터 결과와 직선으로 예측되는 결과와는 완전히 일치를 하지 않습니다. 대략적으로 추정이 가능한 정도의 수준입니다. 이때의 h함수를 Und.. 2016. 7. 19. 이전 1 다음