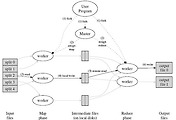
분산환경의 빅데이터 서버를 구성하기 위해서는 apache hadoop을 많이 사용하고 있습니다.
데이터가 점차 중요해지는 시기가 되고 있고 엄청나게 많은 데이터가 넘쳐나고 있는 지금의 세상에서 어쩌면 가장 필수적인 서버 환경이 되지 않을까 싶은 생각이 듭니다.
그래서, 올해 마지막이자, 개인적인 연말 프로젝트로 시작하는 분산컴퓨팅 환경을 구축하려고 합니다.
ubuntu 14 서버 총 4대를 가지고 hadoop cluster 환경을 구축하고 이어서 spark까지 해보도록 하겠습니다.
워낙 길고 긴 여정이 될 내용인지라 너무 길어서 조금 나눠서 올릴 계획입니다.
아마 3~4부 정도 되지 않을까 싶으네요.
서버 환경 구성하기
일단 hadoop을 설치하기 전에,
4대의 ubuntu 서버들 모두에게 공통적으로 기본 환경 구성에 필요한 내용들을 먼저 해주어야 합니다.
1. user/usergroup 생성
모든 서버에 hadoop 사용자 그룹과 유저를 생성하고 권한을 부여해 줍니다.
$ sudo addgroup hadoop
$ sudo adduser --ingroup hadoop hduser
### sudoers file에 hduser 추가
2. ssh 설정
hadoop은 분산처리시에 서버들간에 ssh 통신을 자동적으로 수행하게 됩니다.
이를 위해서 암호입력 없이 접속이 가능하도록 ubuntu0 서버에서 공개키를 생성하고 생성된 키를 각 서버들에 배포해줍니다.
### ssh 설정 변경
$ sudo vi /etc/ssh/sshd_config
----------------------------------------------------------------------------------
PubkeyAuthentication yes
AuthorizedKeysFile .ssh/authorized_keys
### 공개키를 생성
$ mkdir ~/.ssh
$ chmod 700 ~/.ssh
$ ssh-keygen -t rsa -P ""
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
### 공개키를 각 서버에 배포
$ ssh-copy-id -i ~/.ssh/id_rsa.pub ubuntu1
$ ssh-copy-id -i ~/.ssh/id_rsa.pub ubuntu2
$ ssh-copy-id -i ~/.ssh/id_rsa.pub ubuntu3
### 접속 테스트
$ ssh ubuntu1
3. java 설치
Hadoop이 JVM을 사용하기 때문에 모든 서버에 java SDK를 설치하도록 합니다.
현재 Hadoop 버젼이 2.7.* 이며, 버젼 2 이상부터는 java 1.7 이상에서만 지원이 되기에 이미 설치가 되어 있다면 버젼확인을 해보시길 바랍니다.
여기서는 현재 최신 버젼인 java 1.8을 설치하겠습니다.
$ sudo mkdir /opt/jdk
$ cd /opt
### Download archive
### Unpack
### Update Ubuntu alternatives symbolic links
$ sudo update-alternatives --install /usr/bin/java java /opt/jdk/jdk1.8.0_111/bin/java 100
java 버젼정보가 보여지면 정상적으로 설치가 잘 되었습니다.
4. locale 확인(옵션)
모든 서버의 locale 정보를 확인해보고 en_US.UTF-8 혹은 ko_KR.UTF-8 이 아닌 경우에만 변경을 해주면 됩니다.
일반적으로는 변경할 필요가 없으니 옵션사항으로 생각하시고 skip 하시면 되겠습니다.
### 정보 확인
5. hosts 파일 수정
분산 환경이기 때문에 4대의 서버 모두에 접속이 자유롭게 되어야 합니다.
이를 위해서 모든 서버들의 hosts 파일에 ip와 host 이름을 생성해 주도록 합니다.
참고로 여기서는 ubuntu0이 master 서버가 될 예정이고, 그외 서버들은 slave 서버가 될 예정입니다.
### hosts 파일 수정
10.1.1.15 ubuntu2
10.1.1.221 ubuntu3
$ cat /etc/hosts
6. hostname 변경
각각 4대 서버들의 이름을 위에서 지정한 host 이름과 동일하게 맞춰주도록 합니다.
### ubuntu0 서버의 경우
$ sudo vi /etc/hostname
----------------------------------------------------------------------------------
ubuntu0
### 변경사항 적용하기 (서버 재부팅 필요없음)
$ sudo /bin/hostname -F /etc/hostname
여기까지 되면 기본적인 서버들의 환경설정이 모두 완료되었습니다.
다음에는 Hadoop을 설치하고 구동해보도록 하겠습니다.
'Hadoop' 카테고리의 다른 글
| Ambari 설치 : Hadoop 에코시스템의 설치/관리 및 모니터링 (0) | 2017.01.15 |
|---|---|
| Hadoop Cluster & Spark 설치하기 - 3.Spark 설치 (3) | 2016.12.24 |
| Hadoop Cluster & Spark 설치하기 - 2.Hadoop 설치 (17) | 2016.12.23 |
| 빅데이터 분산 컴퓨팅 (Hadoop) (2) | 2016.12.12 |


댓글