Tensorflow 에서 제공하는 특별한 패키지들이 있습니다.
이번에는 tf.contrib.learn Quickstart 튜토리얼을 통해서 이 라이브러리를 사용하면 얼마나 쉽게 구현을 할 수 있는지 알아보겠습니다.
<tf.contrib.learn Quickstart 튜토리얼>
참고로 Tensorflow 사이트를 보실때 가능하면 오리지널 사이트에 있는 master 버젼으로 보는게 좋겠습니다. 이번 예제를 하면서 최신버젼(현재 r11)을 보면서 했는데도 예제가 오류가 발생해서 한시간동안이나 수정하고 있었는데, 우연히 master 버젼을 보고 이미 수정이 되어 있어서 완전 허탈했네요.ㅜㅜ
여튼 이런 삽질은 정말 피하고 싶으니 가능하면 master 버젼의 문서를 보는게 좋겠습니다.
튜토리얼 사이트를 먼저 읽어보시고 중간쯤에 위치해 있는 두개의 csv 파일을 다운로드 받아서 서버에 upload 해놓습니다.
A training set of 120 samples (iris_training.csv)
A test set of 30 samples (iris_test.csv).
그리고 소스를 실행을 시켜보면 정상적으로 결과가 나타납니다.
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import tensorflow as tf
import numpy as np
# Data sets
IRIS_TRAINING = "iris_training.csv"
IRIS_TEST = "iris_test.csv"
# Load datasets.
training_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TRAINING,
target_dtype=np.int,
features_dtype=np.float32)
test_set = tf.contrib.learn.datasets.base.load_csv_with_header(
filename=IRIS_TEST,
target_dtype=np.int,
features_dtype=np.float32)
# Specify that all features have real-value data
feature_columns = [tf.contrib.layers.real_valued_column("", dimension=4)]
# Build 3 layer DNN with 10, 20, 10 units respectively.
classifier = tf.contrib.learn.DNNClassifier(feature_columns=feature_columns,
hidden_units=[10, 20, 10],
n_classes=3,
model_dir="/tmp/iris_model")
# Fit model.
classifier.fit(x=training_set.data,
y=training_set.target,
steps=2000)
# Evaluate accuracy.
accuracy_score = classifier.evaluate(x=test_set.data,
y=test_set.target)["accuracy"]
print('Accuracy: {0:f}'.format(accuracy_score))
# Classify two new flower samples.
new_samples = np.array(
[[6.4, 3.2, 4.5, 1.5], [5.8, 3.1, 5.0, 1.7]], dtype=float)
y = list(classifier.predict(new_samples, as_iterable=True))
print('Predictions: ', y[0] ,',', y[1])
>>
Accuracy: 0.966667
Predictions: [1] , [1]
이전의 예제보다 소스가 훨씬 간결해졌습니다.
다운받은 csv 데이터로 부터 training set과 test set을 load_csv_with_header() 함수를 사용해서 로딩합니다.
이제 이 feature 데이터를 담을 연속적인 feature_columns 를 생성합니다. tf.contrib.layers.real_valued_column() 함수를 이용해서 4차원 배열의 데이터를 생성합니다. 다운로드 받은 csv 데이터가 꽃잎과 꽃받침에 대한 가로,세로 길이 정보로 4가지 features로 되어 있기 때문입니다.
이제 DNN 모델을 생성하기 위해서 tf.contrib.learn.DNNClassifier() 함수를 사용합니다. 아주 간단하게 NN 모델을 만들수 있으며 hidden_units 옵션 값을 통해서 각 Layter의 Units 수를 지정할 수도 있습니다.
이렇게 단 한줄의 구현으로 쉽게 모델을 만들 수 있습니다.
만들어진 모델에 fit() 함수를 사용해서 학습시킬 데이터와 steps 수를 지정해주고,
evaluate() 함수를 사용해서 정확도를 평가합니다.
여기서 나타난 정확도 결과는 무려 96%나 됩니다. 몇줄 되지도 않는데 말이지요
이제 새로운 샘플 데이터를 통해서 이미 학습되어진 모델를 활용해 예측결과를 볼 수 있습니다. predict() 함수를 사용하면 됩니다.
여기서 사용된 새로운 데이터는 1,2가 나와야 정상인데 저는 여러번 돌려보니 계속 1,1이 나오네요 ㅎㅎ
이렇게 간단하게 수행을 했는데
이 함수들이 자동으로 모델도 만들어주지만 로깅도 하도록 되어 있습니다.
그래서 model 디렉토리가 생성되고 그 안에 여러 파일들이 자동으로 생성이 됩니다.
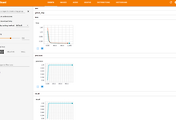
우리는 이 파일들을 이용해서 TensorBoard 상에서 여러 정보들을 그래프로 쉽게 볼 수 있습니다.

이렇게 이미 잘 만들어 놓은 api 들을 활용하면 아주 쉽게 모델을 구현할 수 있을 것 같습니다.
그리고 선형모델에 대해서 잘 설명해 놓은 튜토리얼이 있으니 꼭 한번은 읽어 보시길 추천합니다.
https://tensorflowkorea.gitbooks.io/tensorflow-kr/content/g3doc/tutorials/linear/overview.html
'Tensorflow' 카테고리의 다른 글
| 15. Tensorflow 시작하기 - Logging & Monitoring (0) | 2016.11.13 |
|---|---|
| 14. Tensorflow 시작하기 - Wide & Deep Learning (0) | 2016.11.08 |
| 12. Tensorflow 시작하기 - TensorFlow Mechanics 101 (0) | 2016.11.06 |
| 11. Tensorflow 시작하기 - TensorBoard (0) | 2016.11.05 |
| 10. Tensorflow 시작하기 - flags (3) | 2016.11.04 |


댓글