지금까지 배운 머신러닝에 대한 내용을 토대로하여 photo OCR 시스템을 만들어 보도록 하겠습니다.
이것을 통해서 우리는 지금까지 배운 모든 내용들을 종합적으로 사용하는 것을 배우며, 또 머신 러닝 시스템을 구축하기 위한 pipeline에 대해서 알아볼 것입니다.
먼저 photo OCR이란 photo optical character recognition을 말합니다. 즉 사진에 찍혀있는 문자들을 인식하는 것입니다. 최근에 스마트폰등의 보급으로 디지털 카메라를 모두 사용하기 때문에 이러한 사진을 많이 가지고 있습니다. 이런 사진들을 인식하기 위한 하나의 방법이 되는 것입니다. 이를 이용해서 다양하게 실생활에 활용도 가능할 것입니다. 예를들어, 사진 정보를 이용해서 사진을 분류하거나 검색하는데 사용도 될 수 있고, 또 시각장애인들이 전방에 상황을 카메라로 찍으면 문자정보를 읽어주어 현재 상황을 판단하도록 할수도 있겠지요. 이런식으로 네비게이션으로도 활용이 될 수 있을 겁니다.
하지만 일반적인 문서에서 글자를 인식하는 것보다 사진에서 글자를 인식하는 것은 매우 어려운 일입니다. 아래 그림과 같이 상점앞을 찍은 사진이 있습니다. 이 상점 사진에는 빨간색 박스로 표시한 것과 같이 글자들이 있습니다. 사람은 이것을 보고 바로 인지를 할 수 있지만 컴퓨터에게는 눈이 없어서 그게 쉽지 않은 일입니다.

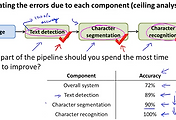
Photo OCR을 처리하기 위한 순차적인 방법(pipeline)에 대해서 살펴보겠습니다. 아래 그림과 같이 크게 3가지 단계로 진행이 될 것입니다. 먼저 사진에서 글자(text)들을 찾아냅니다. 그리고 이 글자들을 한글자씩 구분을 해줍니다. 이렇게 생성된 한글자의 이미지를 분류하여 실제 text로 변환을 하는 과정이 되겠습니다.
그리고 한글자의 이미지를 text로 변환할 때 오타가 있다면 수정하도록 할 수도 있을 것입니다. 예를들어 C1eaning 을 수정하여 Cleaning과 같이 말입니다.

이러한 pipeline을 도식화하면 아래 그림과 같이 표현이 됩니다. 이미지를 가지고 와서 text를 찾고 찾은 text 이미지를 한글자씩으로 구분하고, 이 글자 이미지를 분류하여 text로 변환하는 것이지요
이러한 Pipeline은 머신러닝 시스템을 구축하는데 유용하게 많이 사용이 됩니다. 이를 통해서 각각의 단계별 작업을 모듈화 할 수 있고 이렇게 모듈화된 작업을 보통은 1~5명으로 구성된 팀 단위로 개발을 진행하게 되기 때문입니다. 자연스럽게 협업이 가능하도록 작업 구성을 짜는대도 유용합니다.

Sliding window image analysis
다음의 두가지 사진이 있습니다. 왼쪽은 우리가 하려고 하는 사진이고 오른쪽은 거리를 지나가고 있는 행인들의 모습이 담긴 사진입니다. 이 두가지 사진을 잠시 비교를 해보면 차이점이 보입니다. 가장 큰 차이점이자 computer vision에서 문제가 되는 것이 바로 다른 사이즈의 박스로 인식이 되어지는 결과물에 대한 것입니다. 왼쪽 사진은 문자로 인식이 되는 이미지의 크기(빨간색 박스의 크기)가 다양하게 나타나는데 반면에, 오른쪽 사진은 사람들의 크기가 비슷하여 인식되는 이미지가 일정한 비율로 유지가 되는 것을 알 수 있습니다. 이로 인해서 컴퓨터가 인식하기에는 왼쪽의 사진이 더 까다롭고 어렵습니다.

먼저 심플한 오른쪽의 사진을 가지고 Sliding window 방식을 알아보겠습니다. 일정한 픽셀을 갖는 이미지 데이터를 준비합니다. 여기서는 82x36 크기의 이미지를 사용합니다. 이 사이즈는 사람의 비율에 맞게 일반적으로 많이 사용되는 사이즈입니다. 그래서 사람이 있는 이미지는 y=1로 사람이 없는 이미지는 y=0으로 하여 분류를 합니다. 이것을 Supervised learning으로 학습을 하면 사람 이미지를 찾아낼 수 있게 될 것입니다.
이런 이미지 데이터가 약 1000~10,000개 정도 training set으로 사용하여 neural network으로 구성하면 좋을 것 같습니다.

82x36 patch의 녹색박스를 사용하여 이미지 인식을 시작하면 다음과 같은 프로세스로 진행이 됩니다. 처음 시작은 이미지의 상단 왼쪽부터 시작해서 녹색 박스가 오른쪽으로 약 4 pixel 씩 순차적으로 이동하면서 이미지를 스캔하고 각 스캔된 조각이 사람의 이미지인지 아닌지를 판단합니다. 만약 사람의 이미지가 아니라고 판단이 되면 y=0의 결과가 되겠지요.
이렇게 이동하는 크기를 step-size 혹은 stride 라고 합니다. 이 크기가 만약 1 pixel이라면 1픽셀씩 이동하면서 이미지를 스캔하게 되는 것인데 이렇게 되면 데이터 처리량이 많아지므로 연산 비용이 아주 커질 것입니다. 그래서 보통은 5~8 pixels 정도로 사용합니다.
이렇게 하여 전체 이미지를 모두 스캔하고 인식하여 찾아낸 사람 이미지를 나타낼 수 있게 되는 것입니다.






우리의 상점 사진으로 다시 돌아가서 위와 같은 방식으로 글자들의 이미지와 글자가 없는 배경 이미지들을 준비하고 학습을 시켜 놓습니다.

그리고 위에서 같이 이미지를 스캔하고 인식하도록 합니다. 이러한 방식을 Sliding window classifier 라고 합니다. 고정된 크기의 사각형 모양을 이용해서 이미지를 분석하는 것이지요
이렇게 문자로 인식되어 있는 이미지는 white색으로 만들고, 그렇치 않은 이미지는 black색으로 만들어보면 아래 그림의 검은색에 흰색 얼룩 같아보이는 이미지가 됩니다. 이것은 문자 주위에 빨간색 박스를 치기 위해서 문자들의 길이와 사이즈, 비율을 찾아내기 위한 방법입니다. 아래 왼쪽의 이미지에서 또 다시 pixel들이 흰색 주위에 가까이 있는 것들은 모두 횐색으로 만들어 주면 오른쪽의 이미지와 같이 됩니다. 이렇게 연결되어 있는 흰색 범위의 이미지를 만들면 문자가 속한 박스를 만들수 있게 됩니다. 이때 일반적인 문자나 문장의 크기와는 다른 크기 즉, 세로로 길고 얇게 생겨지는 하단의 흰색과 같은 것들은 무시되도록 할 수 있습니다.

이렇게 인식 타겟이 되는 이미지를 선별했다면 그 다음 pipeline을 진행합니다.
Character Seqmentation
한글자씩으로 구분을 하기 위해서 두가지 문자로서 중앙에 파란색선으로 구분되어 질 수 있는 이미지들을 이용해서 1차원(1D) 이미지의 문장을 처리합니다. 아래 그림의 왼쪽과 같이 세로의 파란색 선으로 구분이 되는 이미지는 y=0으로 그렇치 않는 이미지들은 y=0 으로 하여 supervised learning algorithm을 사용해 classifier를 합니다.

아래와 같이 스캔 및 인식을 하면서 글자들을 한글자씩 분리하게 됩니다.


Character Classificaton
이렇게 한글자의 이미지로 분리를 하였으면 이전에 배운 기본적인 supervised learning algorithm을 사용해서 글자 이미지를 text로 판단할 수 있게 되었습니다. 이것은 multi-class characterization problem 이 됩니다.
'Machine Learning' 카테고리의 다른 글
| 49. 머신러닝 시스템 예제 : Ceiling analysis (0) | 2016.09.12 |
|---|---|
| 48. 머신러닝 시스템 예제 : Aritificial data synthesis (0) | 2016.09.11 |
| 46. 빅데이터 대응하기 : 분산환경 처리하기 (Map Reduce & data parallelism) (0) | 2016.09.07 |
| 45. 빅데이터 대응하기 : 스트림형 데이터 처리하기 (Online learning) (1) | 2016.09.06 |
| 44. 빅데이터 대응하기 : Large Scale Machine Learning (5) | 2016.09.05 |


댓글