지금까지는 결과값이 0,1로 두개로 분류되는 것에 대해서 알아보았습니다.
이번에는 결과값이 여러개로 분류되는 경우에 대해서 알아보겠습니다.
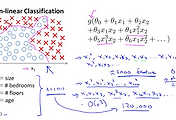
아래 그림의 예제들과 같이 여러개의 케이스로 분류가 되는 경우가 있을 것입니다. 이메일을 분류하기 위해서 직장에서 온 메일인지, 친구에게 온 메일인지, 가족이나 취미활동에서 온 메일인지를 분류하고자 하는 경우 y 결과값이 1,2,3,4의 4가지로 나타낼 수 있습니다.
또 의사 처방시에 이상없음, 감기정도임, 악성 플루로 의심됨과 같이 3가지 분류가 될 수도 있고요
또 날씨에 경우도 맑음, 흐림, 비, 눈으로 분류해서 4가지의 결과값을 가지는 경우도 있을 것입니다.

3가지로 결과가 분류가 되는 케이스에 대해서 생각해봅니다.
1번째 결과는 세모로, 2번째 결과는 네모로, 3번째 결과는 엑스로 되어 있는 dataset을 그래프로 나타내면 아래 그림과 같다고 합시다.
지금까지 배운 binary classification에서는 두개의 결과값을 구분하는 직선 혹은 곡선의 경계선을 생성하여 구분하였습니다. multiclass일 경우에서는 one vs all의 방식을 사용하게 됩니다. 즉, 1번째 결과와 그 나머지를 분류하고, 2번째 결과와 그 나머지를 분류하는 식으로 말입니다.
아래 그림의 오른쪽 그래프와 같이 y가 1일 경우에는 세모와 나머지로 구분을 하고 y가 2일 경우에는 네모와 나머지로 구분을 하며, y가 3일 경우에는 엑스와 나머지로 구분하는 Decision Boundary를 생성하고 조합하는 방법입니다.

이 One-vs-all 방식을 정리를 하면 아래 그림과 같습니다.
logistic regression의 구분자가 되는 h 함수는 각각의 i class에 대해서 y가 i가 되는 가능성을 나타냅니다.
여기서 새로운 데이터 x가 추가되었다고 할때 이를 예측하기 위해서는 i class가 가장 큰 가능성을 나타내는 것을 선택하면 되겠습니다.
즉, i class의 모든 h함수에 대해서 예측값을 구한 다음 가장 값이 큰 class가 해당 x가 속하게 되는 최종 결과(분류/Class)가 됩니다.

'Machine Learning' 카테고리의 다른 글
| 19. 뇌신경망을 활용한 머신러닝 개념 (Neural Networks) (1) | 2016.07.20 |
|---|---|
| 18. 모델의 과최적화를 피하는 방법 (overfitting, regularization) (8) | 2016.07.19 |
| 16. Logistic Regression을 처리하는 방법 (5) | 2016.07.16 |
| 15. Supervised Learning - Classification 표현 (12) | 2016.07.15 |
| 14. [실습] Linear Regression 구현해보기 (Octave) (0) | 2016.07.14 |



댓글