자 이제 그동안에 배웠던 내용을 다시 기억해봅니다.
이전에는 집의 사이즈에 대한 집 매매가격에 대한 예제 dataset를 가지고 했었는데요
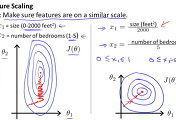
집의 가격에 영향을 미치는 요인이 단지 사이즈만 존재하는 것은 아니겠지요. 그래서 data(feature)를 더 추가해보려고 합니다. 아래 그림에서와 같이 방의 갯수, 층수, 건물이 지어진 년수와 같은 3가지 data를 추가하였습니다.
1번째 데이터를 보면 집에 사이즈는 2104피트이고 방이 5개가 있고 1층으로 지어진 45년전에 지어진 집의 가격이 460,000달러가 되겠습니다. 각각의 집에 가격에 영향을 미치는 x의 항목들을 순서대로 x1, x2, x3, x4라고 표현을 했습니다. 총 4개의 data(features)가 되고 features의 객수를 n이라고 표현했습니다. n은 4가 되겠지요. 집의 가격은 이전과 동일하게 y로 표현이 됩니다.
그리고 이 dataset의 갯수인 m은 47로 표시가 되어 있으니 47채의 집에 대한 데이터가 있다는 것을 알수 있습니다.
x(2)라고 표현을 하면 두번째 집에 대한 data를 의미하는 것이고 이 집에 대한 data는 4개의 features로 구성이 되어 있으니 아래 그림의 분홍색 글씨와 같이 Vector로 표현이 가능합니다.
x3(2)라고 표현을 하면 두번째 집에 대한 data를 역시 의하며, 이 집에 대한 data중에서 2번째의 featrure를 의미하게 되고 이 값은 2층을 나타내게 됩니다.

이제 h함수를 다시 보겠습니다.
이전에는 x가 집에 사이즈 하나였었으나 이제는 x가 4개로 늘어났으니 공식이 어떻게 바뀌는지 알아보겠습니다.
아래와 같이 x1에서 x4까지 추가가 되었고 h함수의 길이가 길어졌습니다.
h 값이 y가 되는 것을 찾는 것이 우리의 목표였죠. x로 표현되는 4개의 features을 대입해서 계산을 해보면 아래 그림의 예제와 같이 계산이 가능합니다.

만약 features의 갯수인 n이 4개가 아니라 무한이 많아진다면 어떻게 표현할 수 있을까요
아래와 같이 x1에서 xn까지의 합으로 나타낼 수 있습니다. 세타도 마찬가지로 n개로 늘어나게 되겠습니다. 상수값이 되는 세타zero는 1을 곱해도 값이 변하지 않으니까 1을 x0으로 표현을 해도 공식이 바뀌지는 않을것입니다. 그럼 공식이 좀더 일관성있게 표현이 가능해지겠습니다.
그래서 X matrix는 x0~xn까지의 features를 나타내고 여기서 features의 갯수는 n+1개가 됩니다. (0부터 시작하기 때문입니다)
같은 방식으로 세타 matrix는 세타0~세타n까지의 parameters를 나타내고 features의 갯수는 n+1개가 됩니다.
두개의 Vector가 같은 방향으로 되어 있기 때문에 곱하기 연산이 되지 않겠죠
그래서 세타 Vector를 transpose를 해줍니다. 그러면 아래 그림의 오른쪽 부분과 같이 (n+1)x1 matrix가 되어 x matrix와 곱하기 연산이 가능해지므로 세타T라고 표현합니다. 앞으로 T(transpose)를 h함수의 parameter로 자주 사용하게 될 것입니다.

Gradient Descent for Multiple Features
이번에는 Gradient Descent Algorithm에 적용을 해보겠습니다.
h 함수가 세타T와 x의 곱하기로 심플해지는 것을 위에서 배웠습니다. 각각의 세타와 x는 Vector였죠
n+1개의 크기를 갖는 Vector로 세타가 변경이 되었으니 이것을 Cost 함수인 J 함수에 적용을 해보면 아래 그림과 같이 됩니다. 특별한 것은 없고 좀더 심플하게 표현이 되는 것입니다. J(θ)
알고리즘에서도 세타 Vector가 하나로 표현이 됩니다.

각 parameter 별로 풀어놓은 것입니다.
왼쪽은 parameter가 1개 였을때 봤던 공식이고 오른쪽은 parameters가 n+1개인 알고리즘 공식이 되겠습니다. 각각의 parameter로 편미분을 하면 세타zero의 식이 나오고 세타one의 식이 나옵니다. 이 두개의 식에 차이점은 x가 있느냐 없는냐의 차이였었지요
오른쪽에 식을 보시면 우리가 x0=1로 놓고 추가하였기 때문에 모든 식에 x가 일관성있게 나타나고 결국 세타zero의 공식은 왼쪽이나 오른쪽이 같은 식이 된다는 것을 알수 있습니다.

이처럼 features가 많이 늘어나더라도 결국 같은 식이 되며 표현이 심플해지는 것을 알 수 있습니다.
'Machine Learning' 카테고리의 다른 글
| 10. Feature를 선택하는 방법과 다항식 모델(Polynomial regression) 인 경우 (0) | 2016.07.11 |
|---|---|
| 9. Gradient Descent Algorithm 사용시 유의할 점 (0) | 2016.07.10 |
| 7. 매트릭스와 벡터 계산하기(Linear algebra) (0) | 2016.07.07 |
| 6. 머신이 학습하는 알고리즘 (Gradient descent algorithm) (6) | 2016.07.05 |
| 5. 결과 값을 비교하는 방식(Cost function) (6) | 2016.07.04 |



댓글