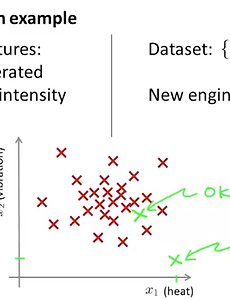
variance4 RL (강화학습) 기초 - 7. Temporal-Difference Learning TD 방식도 마찬가지로 직접적인 경험을 하면서 학습을 하는 알고리즘입니다.DP에서 사용하던 bootstrapping을 사용하고 MD에서 사용하던 Model-free 방식의 장점을 두루 갖추고 있는 것이 특징입니다. every-visit MC에서는 실제 에피소드가 끝나고 받게되는 보상을 사용해서 value function을 업데이트 하였습니다.하지만 TD에서는 실제 보상과 다음 step에 대한 미래추정가치를 사용해서 학습을 하게 됩니다.이때 사용하는 보상과 value function의 합을 TD target이라고합니다.그리고 이 TD target과 실제 V(S)와의 차이를 TD error 라고 하고 델타라고 표현을 합니다. MC에서의 value function이 업데이트 되는 과정을 위 왼쪽의 그림과 같이.. 2017. 11. 1. 38. 이상(사기) 탐지 : Anomaly Detection System 개요 Anomaly Detection우리가 사용하는 dataset에는 수많은 데이터들이 있습니다. 이중에서 모든 데이터가 정상일 수도 있지만 그렇치 않을 수도 있을 것입니다. 이제부터는 특정 데이터가 이상이 있는지를 파악하기 위한 방법에 대해서 알아보고자 합니다.이상한(비정상적인) 데이터를 검출하는 것을 Anomaly Detection 이라고 합니다. 아래 그림에서와 같이 예를들어서 살펴보겠습니다. 비행기 엔진을 만드는 제조사를 생각해보겠습니다. 엔진은 열이 높아짐에 따라서 엔진의 회전이 빨리질 것이라고 생각해볼수 있을 것입니다. 아래 그래프의 데이터들과 같이 분포되어 있는 것을 볼 수 있습니다. 이때 녹색의 x 데이터와 같이 다른 데이터들과 밀접한 부분에 존재하는 경우는 정상적인 데이터라고 볼수 있으나 나홀.. 2016. 8. 24. 30. SVM (Support Vector Machine) - Kernel에 대하여 Kernel이번에는 non-linear 에 대해서 알아보겠습니다. 아래 그림과 같이 dataset이 있고 h 함수가 오른쪽 공식과 같습니다. x 에 대한 다항식을 f로 치환하면 아래쪽의 함수와 같이 나타낼 수 있었습니다. 여기서 f를 어떻게 하면 잘 선택을 할 수 있을지에 대해서 살펴보려고 합니다. 임의로 세개의 점을 아래 그래프와 같이 지정을 해보겠습니다. 이 점들을 l 이라고 표현하고 landmarks라고 읽습니다. 어떠한 data x에 대해서 f를 x, l에 대한 similarity(유사성)의 함수라고 하겠습니다. 이것은 또 수학적으로 표현을 하면 다음과 같이 됩니다.exp(- (|| x - l1 ||^2 ) / 2σ^2)이것의 의미는 x와 l1과의 euclidean distance 값에 제곱을 s.. 2016. 8. 14. 25. 머신러닝을 적용할때 고려할 내용들 (Model Selection, Bias, Variance, Learning Curves) 이번에는 머신러닝을 적용하여 여러분이 원하시는 무언가를 진행하고자 할때 생각해보면 좋은 내용들을 알아보겠습니다. 여러분이 정규화된 linear regression을 예측하는 모델을 만들었다고 생각해보겠습니다. 그런데 실제 학습된 결과가 실제 결과 보다 생각보다 많이 차이가 나서 적용하기 어렵다고 느껴질 때가 있을 것입니다. 이때 무엇을 해야 할까요 일반적으로 사람들은 다음과 같은 내용들을 하려고 생각합니다.1. 더 많은 데이터가 필요하다 - 2배, 10배 되는 데이터가 있으면 더욱 정확한 결과가 가능할 것이다라고 생각하지만 실제로는 그렇치 않습니다.2. features를 더 줄이자- overfitting 이 일어나는것 같아서 이를 방지하기 위해서 더 줄이려고 하는 경향이 생깁니다.3. features를 .. 2016. 7. 26. 이전 1 다음