이번에는 데이터를 압축 (Data Compression) 하는 방법에 대해서 알아보겠습니다.
실제 데이터를 압축하는 것은 아니고 다차원의 데이터를 저차원의 데이터로 축소하는 방식입니다. 이것은 머신러닝을 수행할 때 메모리와 디스크 사용에 대한 비용을 줄일 수도 있지만 그보다 더 좋은 점은 머신이 학습하는 시간을 단축할 수 있다는 것입니다. 더 빠른 결과를 볼 수 있고 성능이 좋은 머신러닝 시스템을 만들 수 있게 되는 것이지요
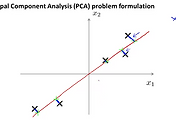
아래 그림을 예로 들어서 살펴보겠습니다. x1, x2로 구성이 되는 2차원의 점들을 나타낸 것입니다. 이것은 어떤 하나의 선으로 각각의 점들을 표현할 수 있다고 생각해 보겠습니다. 이 두가지 x1, x2 데이터는 어떤 관계를 가지고 있을 것입니다. cm 와 inch로 표현되는 같은 의미 이면서 다른 단위의 표시라던가 아니면 비행 조정사의 스킬과 마인드에 대한 관계가 형성이 될 수도 있을 것입니다.

이렇게 모든 2차원으로 표현이 되어 있는 데이터를 하나의 선으로 정의할 수 있다면, 아래 그림에서와 같이 이 선에 투영된 점들은 1차원의 점들 처럼 될 수 있습니다. x(1)은 2가지 정보(x1, x2)를 가지고 있는 vector 이지만, z 라는 선에서 보면 z(i)는 1차원의 점이 되어 z1으로 나타낼 수 있습니다. 이러한 원리로 데이터를 압축 또는 차원을 감소 하는 것입니다.

이번에는 아래와 같은 3D의 3차원 데이터를 2차원의 데이터로 만들어 보겠습니다.
왼쪽과 같이 3차원에 데이터들을 어떤 2차원 적인 사각형에 모두 투영할 수 있다고 생각할 수 있을 겁니다. 가운데 그림처럼 z1, z2로 표현이 되는 사각형에 모든 x(i) 데이터들이 투영이 되었습니다. 이 사각형을 다시 오른쪽 그림과 같이 평면으로 보면 2차원의 점들로 나타낼 수 있게 됩니다.
x(i)는 x1, x2, x3의 정보를 포함하는 vector 이지만, 사각형에 투영되어 새로 생성된 z(i)는 z1, z2의 2차원 데이터가 된 vector가 됩니다.
이런 원리로 1000D 을 100D로 낮출 수도 있으며 이것은 시스템의 성능에 긍정적인 역할을 하게 될 것입니다.

Data Visualization
또 다른 방법으로 Data Visualization이 있습니다.
아래와 같이 각 나라별로 경제와 관련된 데이터들이 있다고 생각해보겠습니다. 이 데이터는 나라별로 50가지의 경제 관련, GDP 통게 데이터들로 구성이 되어 있습니다. 50D가 되겠죠

이렇게 50가지의 정보를 다음과 같이 2가지의 정보로 압축을 할 수 있습니다. z1, z2로 구성된 정보로 말입니다.
z1는 각 나라의 GDP 혹은 경제적인 수치에 대한 비교치입니다. 그리고 z2는 각 나라의 GDP 혹은 경제적인 수치를 국민수로 나누어 생성한 비교수치 입니다. 이것으로 국가 경제를 큰 틀에서 살펴볼 수 있게 된 것입니다.

이렇게 생성된 각 나라별 2차원의 데이터를 2차원 그래프로 표현을 하면 아래 그림과 같이 됩니다. USA는 국가의 전체 GDP도 상대적으로 높고 국민1인당 GDP도 높아 보입니다. 또 다른 나라인 Sigapore의 경우에는 국민 1인당 GDP가 높은데 비해 국가 전체 GDP는 상대적으로 높지 않아 보입니다. 이런식으로 각 나라별 경제에 대한 데이터를 상대적으로 표현함으로서 50D를 2D로 줄일 수 있게 되었습니다.

이러한 원리를 기반으로 하여 다음에 배우게 될 Unsupervised Learning의 두번째 알고리즘인 PCA(Principal Component Analysis)에 대해서 알아보겠습니다.
'Machine Learning' 카테고리의 다른 글
| 37. 자율학습 두번째 (Principal Component Analysis) : PCA 적용하기 (0) | 2016.08.23 |
|---|---|
| 36. 자율학습 두번째 (Principal Component Analysis) : PCA Algorithm (0) | 2016.08.22 |
| 34. 자율적으로 학습하기 (Unsupervised Learning) : K means optimization (0) | 2016.08.20 |
| 33. 자율적으로 학습하기 (Unsupervised Learning) : K-means algorithm (0) | 2016.08.17 |
| 32. 자율적으로 학습하기 (Unsupervised Learning) : Clustering (0) | 2016.08.16 |


댓글