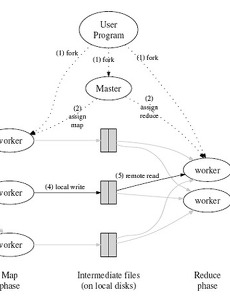
Python1 빅데이터 분산 컴퓨팅 (Hadoop) 빅데이터 저장소 - 1테라 바이트를 약 100MB/S 로 전송한다면 2시간 반 이상 걸린다.- 100개의 드라이브가 있고, 각 드라이브는 100/1씩 저장하고 병렬로 동작한다면 2분내에 데이터를 읽을 수 있다- 병렬 분산처리를 위해서는 하드웨어 장애와 데이터 분할 결합에 대한 고려가 필요하다.- 하둡은 안정적인 공유저장소(HDFS)와 분산 프로그래밍 프레임웍(맵리듀스)을 제공한다. HDFS - 파일시스템(Storage)- FILE은 Block 단위(64MB or 128MB)로 분할되고 분산되어 저장됨- 분할된 정보는 Name node(master)에 메타정보가 기록이 되고, 실제 분할된 파일은 Data node(Slave)들에 분산되어 저장이 됨- Name node 가 없으면 Data node에 저장된 .. 2016. 12. 12. 이전 1 다음