앞에서 살펴본 data compression 또는 dimensionalilty reduction 을 이용해서 오늘날까지 널리 사용되고 인기있는 알고리즘이 바로 PCA(Principal Component Analysis) Algorithm 입니다.
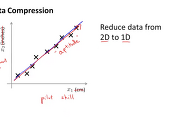
2차원의 데이터를 1차원으로 줄이기 위해서 아래 그림과 같이 직선을 하나 그립니다. 그리고 이 직선에 모든 2차원 데이터들을 투영시켜서 한점으로 나타낼 수 있게 됩니다. 이때의 두 점과의 거리 즉, 2차원 데이터의 점과 직선에 투영되어 생성된 점 사이의 거리를 때로는 projection error 라고 불리우기도 합니다.
이 projection error가 가장 최소화 되는 직선을 찾고 이로 인해서 2차원 데이터를 1차원으로 낮추는대 사용이 됩니다.

만약에 왼쪽 대각선으로 생긴 분홍색의 직선이 있다고 가정해보겠습니다. 이 직선에 투영되어 생성된 점들과 본래의 2차원 데이터들과의 거리를 보면 상당히 긴 거리가 됨을 알 수 있습니다. 이것이 우리가 이전에 배웠던 linear regression과 비슷해 보이지만 다른 점이 되겠습니다. 사실 완전히 다른 알고리즘입니다.

2차원의 데이터들에서 이러한 직선을 찾는 방법은 아래 그림과 같이 2차원 데이터에 vector를 그리고 그 vector가 그리는 직선을 찾는 것입니다. 이때 - 방향의 vector가 되더라도 크게 상관이 없는것이 같은 직선상에 있게 되기 때문입니다. 그렇게 생성된 직선에 projection error가 가장 작은 직선을 찾으면 됩니다.

3차원이 되어도 마찬가지입니다. 2차원으로 낮추기 위해서 2개의 vector를 그리고 이 vector 가 표현하는 사각형의 면을 하나 생성을 합니다. 그리고 3차원의 데이터들이 이 면에 투영되어 생기는 점들과의 거리를 계산해서 가장 적은 projection error가 되는 면을 찾는 것입니다.
이러한 원리로 n차원의 데이터를 k차원으로 낮추기 위해서 k개의 vector가 생성이 될 것이고 이것이 이루는 면에 투영시켜서 가장 적은 projection error가 되는 것을 찾으면 되겠습니다.

위에 잠시 이야기 했던것처럼 PCA는 linear regression과 전혀 다른 알고리즘입니다. 매우 비슷해 보이기는 하지만 가장 다른 점은 y가 예측된 결과값이 였으나 여기서는 그런 값이 없다는 것입니다. 결과를 예측하기 위해서 비슷한 값이 되는 직선을 찾는 linear regression과는 달리 투영하기 위한 가장 최소 거리를 갖는 직선 또는 면을 찾는 것이 PCA algorithm이 되겠습니다. 이때 투영이 되면서 직선과 수직상의 거리를 측정하게 되는 것이 가장 큰 차이점이 됩니다. (vertical distance)

Preprocessing (feature scaling / mean normalization)
PCA 알고리즘을 수행하기 이전에 prepocessing 을 먼저 하는것이 좋습니다. 우리가 supervised learning에서 배운것과 거의 동일한 방식으로 하면 됩니다. 여기에는 두가지 방법이 있는데 하나는 mean normalization 입니다. 이것은 거의 대부분의 경우에 항상 해주는 것이 좋습니다. 아래 그림의 uj 식과 같이 되며 이때 xj - uj 를 xj(i)로 치환하여 사용합니다.
또 다른 하나는 feature scaling 입니다. 이것은 우리의 dataset의 features이 단위가 크게 차이가 날 경우에만 필요에 따라서 사용하면 되겠습니다. 이때에는 xj(i) - uj(i) 를 sj로 나눠주어 xj(i)를 만들어줍니다. 이때 sj 는 max - min 의 값으로 사용해도 되고 일반적으로는standard deviation(표준편차)를 많이 사용합니다.

2차원에서 1차원으로 낮추는 방식에서 핵심은 u(i) vector를 찾는 일입니다. 이 u vector를 기준으로 직선이나 면을 생성하고 모든 x data들을 투영하여 차원을 낮추게 되는 기준이 되기 때문이지요.
이러한 u vector를 수학적으로 풀이하기에는 어려운일이 될수 있습니다. 하지만 한번 알아두면 그다음에는 쉽게 사용이 가능하게 될 것입니다.

PCA algorithm
이제 본격적으로 PCA algorithm에 대해서 알아보겠습니다.
n 차원의 데이터를 k 차원으로 낮추기 위해서는 다음의 두가지 방식을 사용하여 연산을 하게 됩니다.
하나는 Covariance Matrix(공분산행렬)을 이용하는 것입니다. 이것은 두개의 변수에 대한 상관관계를 나타내는 것으로 확률과 통계를 이용한 방식이라고 합니다. 이러한 상관관계를 통해서 두가지 변수에 대한 선형의존도를 나타내기도 합니다. 여기서는 아래와 같이 Upper case Sigma 기호로 표현이 되는 공식이 됩니다. 이 sigma는 summation 기호와는 다른 의미이니 혼동 하지 않기를 바랍니다. 이 Sigma는 nx1의 크기를 갖는 x(i)와 1xn의 크기를 갖는 x(i)T와의 곱으로 이루어지므로 nxn의 크기를 갖는 matrix가 됩니다.
또 하나는 Eigenvector(고유벡터)를 이용하는 것입니다. 이것은 선형대수학에서 고유벡터로 불리우는 벡터로서 0이 아닌 값을 가지면서 선형변형이 일어난 이후에도 방향이 변하지 않는 벡터를 의미한다고 합니다. 여기서는 Sigma의 값을 svd로 연산을 하게 되는데 이때의 svd는 Singular Value Decomposition의 약자로서 eigenvector 보다 안정적인 수학적 방식이라고 합니다.

svd(Sigma) 연산으로 부터 얻은 U matrix는 아래 그림의 nxn 크기의 matrix와 같이 생겼습니다. 여기서 우리는 n차원을 k차원으로 낮추기 위해서 u(1)부터 u(k)까지를 사용하여 z vector를 만들게 됩니다. 아래 그림의 하단에 matrix 공식과 같이 z vector는 k 크기를 갖는 vector가 되며, U matrix에서 1부터 k까지를 가지고 와서 Ureduce matrix를 생성하고 Ureduce T * X를 하여 z vector를 연산하게 됩니다.
z = (Ureduce)T * x

mean normalization에 대해서 조금더 살펴보겠습니다.
Sigma는 아래와 같이 x(i) x(i)T로 구성이 되며 이것은 Octave 에서 구현할때 Sigma = (1/m) * X' * X;와 같이 심플하게 됩니다.
또 [U, S, V] = svd(Sigma) 를 Octave 에서 구현할때 Ureduce = U(: , 1:k);로 k 크기로 잘라서 x와 곱하기 연산을 하면 z를 생성할 수 있습니다. z = Ureduce' * X;
이때 x0 값을 고려하지 않고 합니다.

지금까지 배운 차원을 낮추기 위해 사용되는 PCA 알고리즘을 간단하게 요약을 하면 다음과 같습니다.
1. Preprocessing
2. Calculate sigma (covariance matrix)
3. Calculate eigenvectors with svd
4. Take k vectors from U (Ureduce= U(:,1:k);)
5. Calculate z (z =Ureduce' * x;)



댓글